散列表
- 学习散列表——最有用的基本数据结构之一。
- 学习散列表的内部机制:实现、冲突和散列函数。
散列函数
散列函数是这样的函数,即无论你给它什么数据,它都还你一个数字。
如果用专业术语来表达的话,我们会说,散列函数“将输入映射到数字”。你可能认为散列函数输出的数字没什么规律,但其实散列函数必须满足一些要求。
- 它必须是一致的。例如,假设你输入apple时得到的是4,那么每次输入apple时,得到的都必须为4。如果不是这样,散列表将毫无用 处。
- 它应将不同的输入映射到不同的数字。例如,如果一个散列函数不管输入是什么都返回1,它就不是好的散列函数。最理想的情况是,将不同的输入映射到不同的数字。
散列函数准确地指出了目标的存储位置,你根本不用查找!之所以能够这样,具体原因如下。
- 散列函数总是将同样的输入映射到相同的索引。每次你输入avocado,得到的都是同一个数字。因此,你可首先使用它来确定将鳄梨的价格存储在什么地方,并在以后使用它来确定鳄梨的价格存储在什么地方。
- 散列函数将不同的输入映射到不同的索引。avocado映射到索引4,milk映射到索引0。每种商品都映射到数组的不同位置,让你能够将其价格存储到这里。
- 散列函数知道数组有多大,只返回有效的索引。如果数组包含5个元素,散列函数就不会返回无效索引100。
结合使用散列函数和数组可以创建了一种被称为散列表(hash table)的数据结构。散列表是你学习的第一种包含额外逻辑的数据结构。数组和链表都被直接映射到内存,但散列表更复杂,它使用散列函数来确定元素的存储位置。
散列表使用数组来存储数据,因此其获取元素的速度与数组一样快。散列表由键和值组成。散列表将键映射到值。
应用案例
散列表被用于大海捞针式的查找。将网址映射到IP地址这个过程被称为DNS解析(DNS resolution),散列表是提供这种功能的方式之一。
使用散列表来检查是否重复,速度非常快。
将散列表用作网站缓存.假设你访问网站facebook.com
- 你向Facebook的服务器发出请求。
- 服务器做些处理,生成一个网页并将其发送给你。
- 你获得一个网页。
Facebook的服务器可能搜集你朋友的最近活动,以便向你显示这些信息,这需要几秒钟的时间。作为用户的你,可能感觉这几秒钟很久,进而可能认为Facebook怎么这么慢!另一方面,Facebook的服务器必须为数以百万的用户提供服务,每个人的几秒钟累积起来就相当多了。为服务好所有用户,Facebook的服务器实际上在很努力地工作。有没有办法让Facebook的服务器少做些工作,从而提高Facebook网站的访问速度呢?
缓存的工作原理:网站将数据记住,而不再重新计算。缓存是一种常用的加速方式,所有大型网站都使用缓存,而缓存的数据则存储在散列表中!
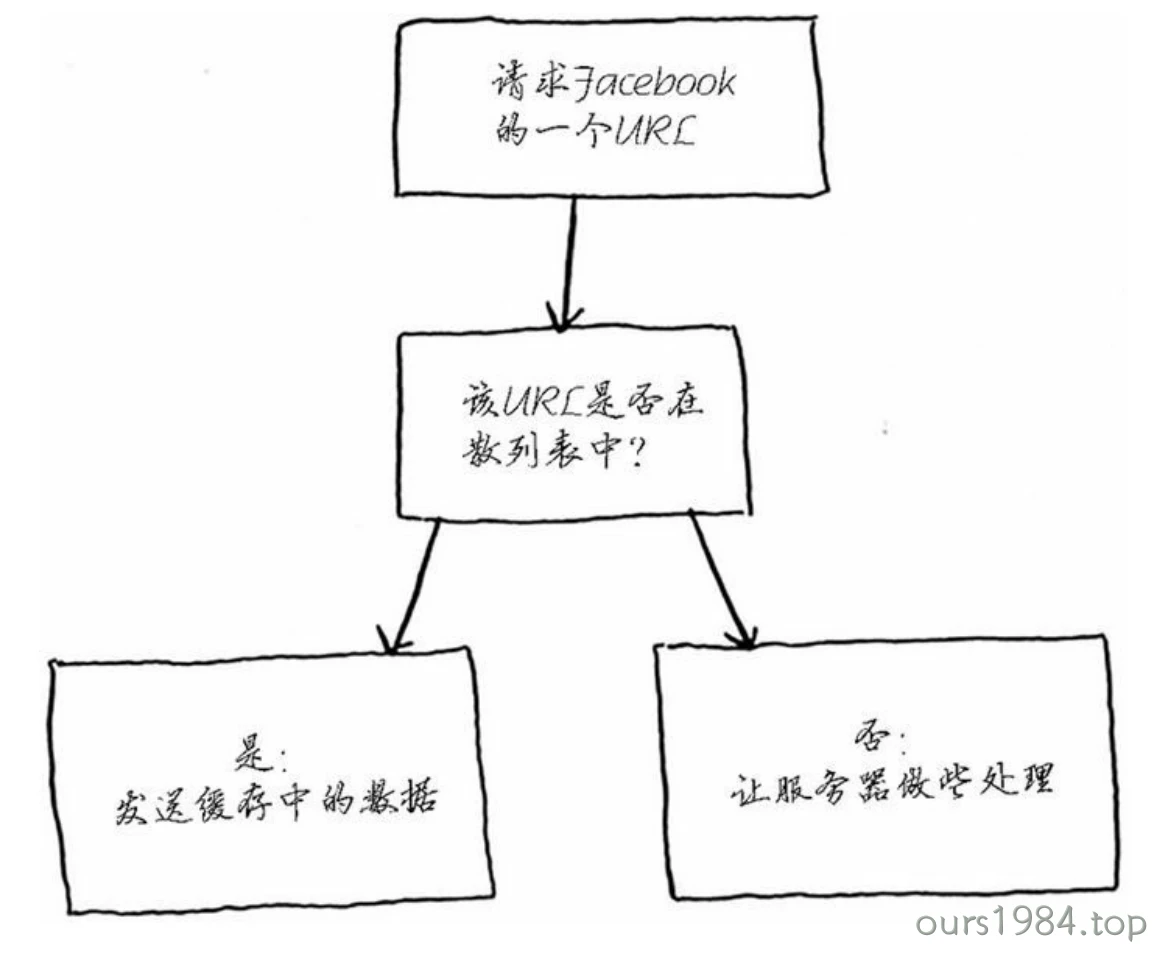
仅当URL不在缓存中时,你才让服务器做些处理,并将处理生成的数据存储到缓存中,再返回它。这样,当下次有人请求该URL时,你就可以直接发送缓存中的数据,而不用再让服务器进行处理了。
案例小结
- 模拟映射关系;
- 防止重复;
- 缓存/记住数据,以免服务器再通过处理来生成它们。
冲突
大多数语言都提供了散列表实现,你不用知道如何实现它们。有鉴于此,我就不再过多地讨论散列表的内部原理,但你依然需要考虑性能!要明白散列表的性能,你得先搞清楚什么是冲突。
实际上,几乎不可能编写出总是将不同的键映射到数组的不同位置的散列函数。这种情况被称为冲突(collision):给两个键分配的位置相同。
冲突很糟糕,必须要避免。处理冲突的方式很多,最简单的办法如下:如果两个键映射到了同一个位置,就在这个位置存储一个链表。
- 散列函数很重要。前面的散列函数将所有的键都映射到一个位置,而最理想的情况是,散列函数将键均匀地映射到散列表的不同位置。
- 如果散列表存储的链表很长,散列表的速度将急剧下降。然而,如果使用的散列函数很好,这些链表就不会很长!
性能
在平均情况下,散列表执行各种操作的时间都为O(1)。O(1)被称为常量时间。你以前没有见过常量时间,它并不意味着马上,而是说不管散列表多大,所需的时间都相同。
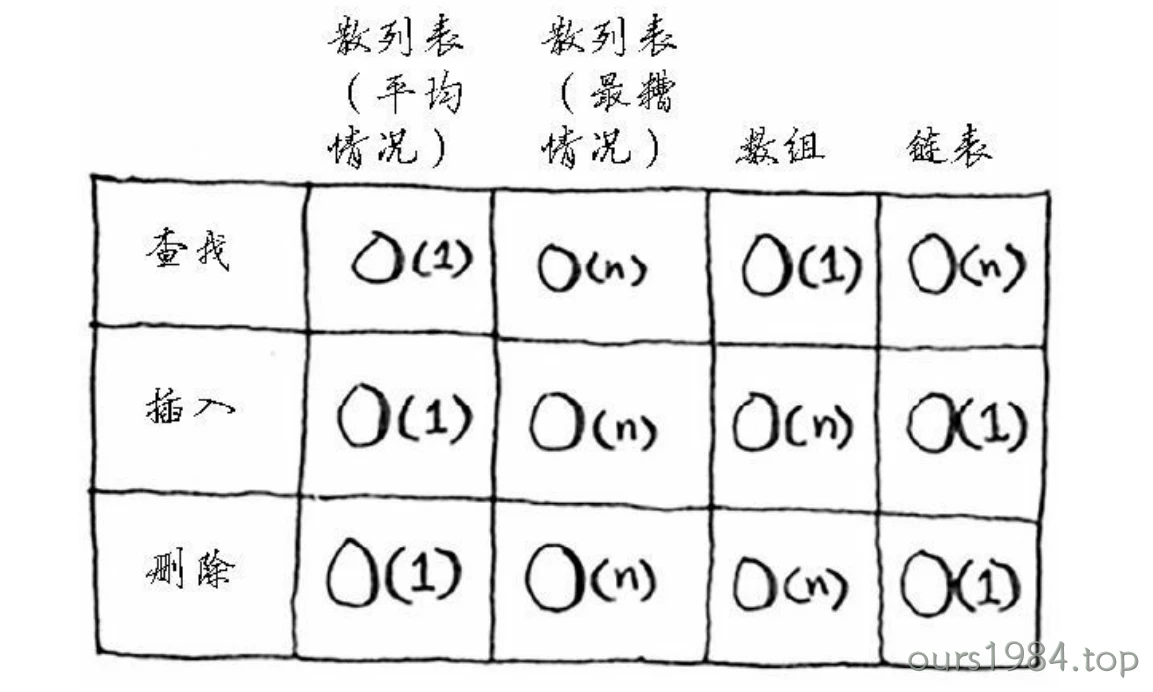
在平均情况下,散列表的查找(获取给定索引处的值)速度与数组一样快,而插入和删除速度与链表一样快,因此它兼具两者的优点!但在最糟情况下,散列表的各种操作的速度都很慢。因此,在使用散列表时,避开最糟情况至关重要。为此,需要避免冲突。而要避免冲突,需要有:
- 较低的填装因子;
- 良好的散列函数。
填装因子
散列表的填装因子很容易计算。元素数/位置总数
填装因子大于1意味着商品数量超过了数组的位置数。一旦填装因子开始增大,你就需要在散列表中添加位置,这被称为调整长度(resizing)
填装因子越低,发生冲突的可能性越小,散列表的性能越高。一个不错的经验规则是:一旦填装因子大于0.7,就调整散列表的长度。调整散列表长度的工作需要很长时间!
良好的散列函数
良好的散列函数让数组中的值呈均匀分布。糟糕的散列函数让值扎堆,导致大量的冲突。
如果你好奇,可研究一下SHA函数。你可将它用作散列函数。
小结
- 你可以结合散列函数和数组来创建散列表。
- 冲突很糟糕,你应使用可以最大限度减少冲突的散列函数。
- 散列表的查找、插入和删除速度都非常快。
- 散列表适合用于模拟映射关系。
- 一旦填装因子超过0.7,就该调整散列表的长度。
- 散列表可用于缓存数据(例如,在Web服务器上)。
- 散列表非常适合用于防止重复。