从零开始学汇编
学习汇编有利于理解c语言本质,也是研究内核必备,同时可用户逆向领域,比如病毒与反病毒,外挂与反外挂,破解与反破解
寄存器详解
通用寄存器
| 数据寄存器 | 解释 | 备注 |
|---|---|---|
| EAX(Accumulator) | 累加寄存器 | 在乘法和除法指令中被自动使用;在Win32中,一般用在函数的返回值中。 |
| EBX(Base) | 基址寄存器 | DS段中的数据指针 |
| ECX(Count) | 计数寄存器 | 在循环指令(LOOP)或串操作中,ECX用来进行循环计数,每执行一次循环,ECX都会被CPU自动减一;c++中保存this |
| EDX(Data) | 数据寄存器 |
| 指针变址寄存器 | 解释 | 备注 |
|---|---|---|
| EBP(Base Pointer) | 扩展基址指针寄存器 | SS段中堆栈内数据指针。EBP由高级语言用来引用参数和局部变量,通常称为堆栈基址指针寄存器。 |
| ESP(Stack Pointer) | 堆栈指针寄存器 | 表示栈顶指针,指向栈顶地址.与SS相配合使用 |
| ESI(Source Index) | 源变址寄存器 | 默认段地址和DI一样,在DS中.和DS联用. |
| EDI(Destination Index) | 目的指针寄存器 | 一般情况下与ds联用,来确定某个储存单元的地址 |
- sp和bp段地址默认在SS中
- sp指向栈顶元素地址.有自加和自减能力,而bp没有.但是bp可以定位栈中某个元素的物理地址.
DI和SI这两个属于变址寄存器.可以和bx.bp联用,但是和bx连用时,段地址在DS中,和bp联用时,段地址在SS中.也可以单独使用,单独使用时,段地址默认在DS中,想要越段使用,加上段前缀即可.
在串指令操作中,si和ds联用,确定目标源地址,di和es(附加段寄存器)联用,确定传送的目的地址.说白了就是,分别寻址数据段和附加段.在串指令中,si和di具有自加和自减功能,
段寄存器
| 寄存器 | 解释 备注 |
|---|---|
| CS(Code Segment) | 代码段 |
| DS(Data Segment) | 数据段 |
| SS(StackSegment) | 堆栈段 |
| ES(Extra Segment) | 附加数据段 |
| FS | 附加数据段 |
| GS | 附加数据段 |
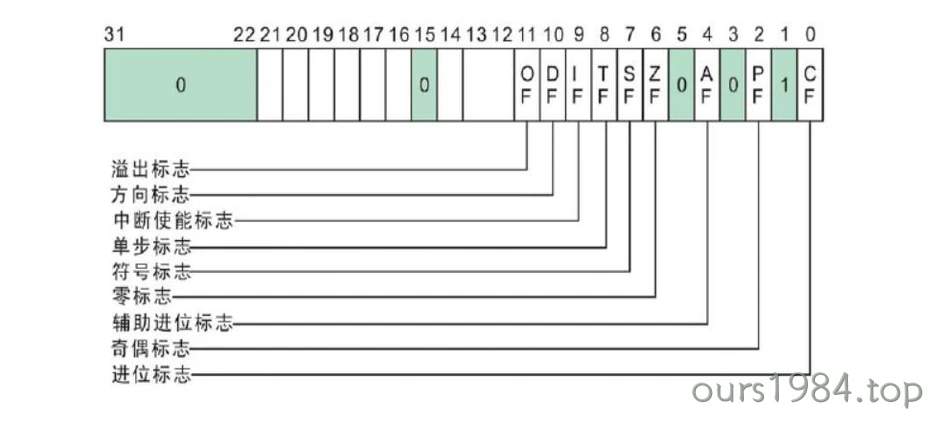
标志寄存器
状态寄存器eflags,没有指令能够直接操作这个寄存器,是CPU根据指令的执行结果,自己操作这个寄存器
| 条件标志寄存器 | 解释 | 备注 |
|---|---|---|
| OF(OverFlow Flag) | 溢出标志位 | 用来反应有符号数加减法运算所得结果是否溢出。运算超出当前运算位数所能表示的范围,则称为溢出,标志位被置为1,否则为0。 |
| SF(Sign Flag) | 符号标志位 | 用来反应运算结果是否为0。运算结果为负时置为1,否则为0。 |
| ZF(Zero Flag) | 零标志位 | 用来反应运算结果是否为 0。为零时置为1,否则为0。 |
| AF(Auxilliary carryFlag) | 辅助进位标志位 | 在字操作址,发生低字节向高字节进位或借位时该标志位被置为1,否则为0。 |
| PF(Parity Flag) | 奇偶标志位 | 用于反应结果中“1”的个数的奇偶性。如果“1”为偶数置为1,否则为0。 |
| CF(Carry Flag) | 进位标志位 | 运算结果的最高位产生了一个进位或错位,则该标志位置为1,否则为0。 |
| 控制标志寄存器 | 解释 | 备注 |
|---|---|---|
| DF(Direction Flag) | 方向标志位 | 用于串操作指令中,控制地址的变化方向。当DF为0时,存储器地址自动增加;当 DF为1时,存储器地址自动减少。 |
| IF(Interupt Flag) | 中断标志位 | 用于控制外部可屏蔽中断是否可以被处理器响应。 |
| TF(Trap Flag) | 陷阱标志位 | 用于控制处理器是否进入单步操作方式。当TF为0时,处理器在正常模式下运行;当为1时,处理器单步执行指令,调试器可以逐步指令进行执行就是使用了该标志位。 |
数据宽度

| 寄存器 | 宽度 | 类型 |
|---|---|---|
| rax | 64bit | long |
| eax | 32bit | int |
| ax | 16bit | short |
| ah | 8bit | ax寄存器的高八位 |
| al | 8bit | al寄存器的低八位 |
汇编指令
数据传输指令
| 寄存器传输 | 说明 |
|---|---|
| MOV | 传送字或字节. |
| MOVSX | 先符号扩展,再传送. |
| MOVZX | 先零扩展,再传送. |
| PUSH | 把字压入堆栈. |
| POP | 把字弹出堆栈. |
| PUSHA | 把AX,CX,DX,BX,SP,BP,SI,DI依次压入堆栈. |
| POPA | 把DI,SI,BP,SP,BX,DX,CX,AX依次弹出堆栈. |
| PUSHAD | 把EAX,ECX,EDX,EBX,ESP,EBP,ESI,EDI依次压入堆栈. |
| POPAD | 把EDI,ESI,EBP,ESP,EBX,EDX,ECX,EAX依次弹出堆栈. |
| BSWAP | 交换32位寄存器里字节的顺序 |
| XCHG | 交换字或字节.(至少有一个操作数为寄存器,段寄存器不可作为操作数) |
| CMPXCHG | 比较并交换操作数.(第二个操作数必须为累加器AL/AX/EAX) |
| XADD | 先交换再累加.(结果在第一个操作数里) |
| XLAT | 字节查表转换.----BX指向一张256字节的表的起点 AL为表的索引值(0-255,即0-FFH) 返回AL为查表结果.([BX+AL]->AL) |
| 标志传输 | 说明 |
|---|---|
| LAHF | 标志寄存器传送,把标志装入AH. |
| SAHF | 标志寄存器传送,把AH内容装入标志寄存器. |
| PUSHF | 标志入栈. |
| POPF | 标志出栈. |
| PUSHD | 32位标志入栈. |
| POPD | 32位标志出栈. |
注意:操作内存,内存地址需要用中括号包起来,不然程序就不能区分是内存地址还是立即数
| 内存传输 | 说明 |
|---|---|
| LEA | 装入有效地址.例: LEA DX,string ;把偏移地址内容存到DX. |
| LDS | 传送目标指针,把指针内容装入DS.例: LDS SI,string ;把段地址:偏移地址存到DS:SI. |
| LES | 传送目标指针,把指针内容装入ES.例: LES DI,string ;把段地址:偏移地址存到ES:DI. |
| LFS | 传送目标指针,把指针内容装入FS.例: LFS DI,string ;把段地址:偏移地址存到FS:DI. |
| LGS | 传送目标指针,把指针内容装入GS.例: LGS DI,string ;把段地址:偏移地址存到GS:DI. |
| LSS | 传送目标指针,把指针内容装入SS.例: LSS DI,string ;把段地址:偏移地址存到SS:DI. |
内存传输其意义是同时给一个段寄存器和一个16位通用寄存器同时赋值 |
| 串传输 | 说明 |
|---|---|
| MOVS | 串传送.( MOVSB 传送字符. MOVSW 传送字. MOVSD 传送双字. ) |
| CMPS | 串比较.( CMPSB 比较字符. CMPSW 比较字. ) |
| SCAS | 串扫描.把AL或AX的内容与目标串作比较,比较结果反映在标志位. |
| LODS | 装入串.把源串中的元素(字或字节)逐一装入AL或AX中. LODSB 传送字符. LODSW 传送字. LODSD 传送双字. ) |
| STOS | 保存串.是LODS的逆过程. |
| REP | 当CX/ECX<>0时重复. |
| REPE/REPZ | 当ZF=1或比较结果相等,且CX/ECX<>0时重复. |
| REPNE/REPNZ | 当ZF=0或比较结果不相等,且CX/ECX<>0时重复. |
| REPC | 当CF=1且CX/ECX<>0时重复. |
| REPNC | 当CF=0且CX/ECX<>0时重复. |
输入输出指令
汇编语言中,CPU对外设的操作通过专门的端口读写指令来完成;
读端口用IN指令,写端口用OUT指令。 例子如下: IN AL,21H;表示从21H端口读取一字节数据到AL IN AX,21H;表示从端口地址21H读取1字节数据到AL,从端口地址22H读取1字节到AH MOV DX,379H IN AL,DX ;从端口379H读取1字节到AL OUT 21H,AL;将AL的值写入21H端口 OUT 21H,AX;将AX的值写入端口地址21H开始的连续两个字节。(port[21H]=AL,port[22h]=AH) MOV DX,378H OUT DX,AX ;将AH和AL分别写入端口379H和378H
运算指令
| 算数运算 | 说明 |
|---|---|
| ADD | 加法. |
| ADC | 带进位加法. |
| INC | 加 1. |
| AAA | 加法的ASCII码调整. |
| DAA | 加法的十进制调整. |
| SUB | 减法. |
| SBB | 带借位减法. |
| DEC | 减 1. |
| NEG | 求反(以 0 减之). |
| CMP | 比较.(两操作数作减法,仅修改标志位,不回送结果). |
| AAS | 减法的ASCII码调整. |
| DAS | 减法的十进制调整. |
| MUL | 无符号乘法.结果回送AH和AL(字节运算),或DX和AX(字运算), |
| IMUL | 整数乘法.结果回送AH和AL(字节运算),或DX和AX(字运算), |
| AAM | 乘法的ASCII码调整. |
| DIV | 无符号除法.结果回送:商回送AL,余数回送AH, (字节运算);或 商回送AX,余数回送DX, (字运算). |
| IDIV | 整数除法.结果回送:商回送AL,余数回送AH, (字节运算);或 商回送AX,余数回送DX, (字运算). |
| AAD | 除法的ASCII码调整. |
| CBW | 字节转换为字. (把AL中字节的符号扩展到AH中去) |
| CWD | 字转换为双字. (把AX中的字的符号扩展到DX中去) |
| CWDE | 字转换为双字. (把AX中的字符号扩展到EAX中去) |
| CDQ | 双字扩展. (把EAX中的字的符号扩展到EDX中去) |
| DS:SI | 源串段寄存器 :源串变址. |
| ES:DI | 目标串段寄存器:目标串变址. |
| CX | 重复次数计数器. |
| AL/AX | 扫描值. |
| D标志 | 0表示重复操作中SI和DI应自动增量; 1表示应自动减量. |
| Z标志 | 用来控制扫描或比较操作的结束. |
| 逻辑运算 | 说明 |
|---|---|
| AND | 与运算. |
| OR | 或运算. |
| XOR | 异或运算. |
| NOT | 取反. |
| TEST | 测试.(两操作数作与运算,仅修改标志位,不回送结果). |
| SHL | 逻辑左移. |
| SAL | 算术左移.(=SHL) |
| SHR | 逻辑右移. |
| SAR | 算术右移.(=SHR) |
| ROL | 循环左移. |
| ROR | 循环右移. |
| RCL | 通过进位的循环左移. |
| RCR | 通过进位的循环右移. |
以上八种移位指令,其移位次数可达255次.移位一次时, 可直接用操作码. 如
SHL AX,1.移位>1次时, 则由寄存器CL给出移位次数.
如 MOV CL,04 SHL AX,CL
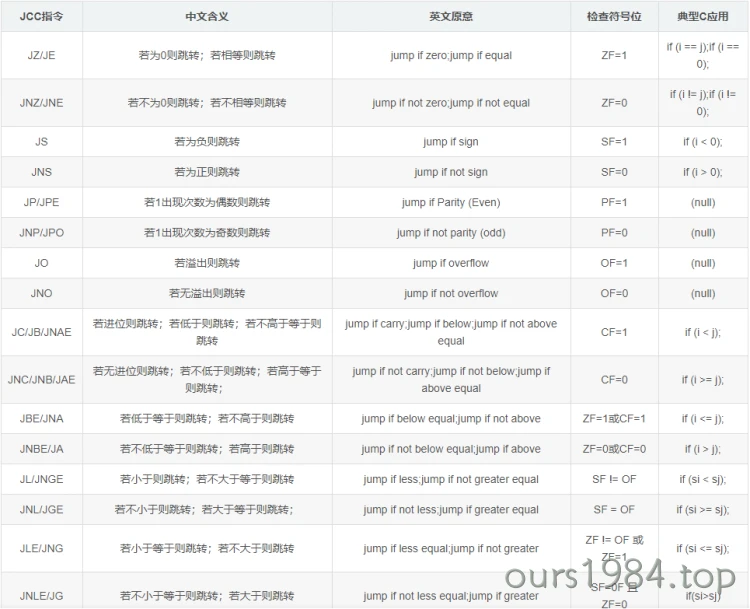
程序转移指令
任何语言的底层,循环结构及条件判断,都是基于cflags寄存器+JCC指令实现的
无条件转移指令 (长转移) |
JA/JB用于无符号数,JG/GL用于有符号数
cmp本质上做减法运算,test本质上做与运算
cmp eax,0 等价于 sub eax,0 差别是cmp的运算结果只会改eflags寄存器,不会修改eax寄存器的值 通常配合JCC指令使用实现条件跳转
test本质上做与运算
test eax,0 等价于 and eax,0 差别是test的运算结果只会改eflags寄存器,不会修改eax寄存器的值 通常配合JCC指令使用实现条件跳转
处理器指令
中断指令 |
masm和nasm
masm是微软专门为windows下汇编而写的,而nasm可以在windows、linux等系统下汇编
nasm 区分大小写,在 nasm 语法里,对 memory 操作数需要加 [ ] 括号,对于 绝对地址 形式,缺省是 32 位的,因此,需要明确使用 qword 来指明 64 位的 address size
伪指令不是 x86/x64 机器的真实指令,伪指令是用于给编译器指示如何进行编译。
dos程序返回
最后两条指令返还控制权给系统单任务程序
mov ax,4c00h |
Intel syntax vs AT&T syntax
- 这是两种不同的汇编语法,可以简单地认为是两种不同的汇编语言
- Intel syntax主要用于DOS和Windows,而AT&T syntax主要用于UNIX。
- AT&T是American Telephone and Telegraph的缩写,AT&T是贝尔实验室的创建者之一,而UNIX系统在贝尔实验室诞生,因此UNIX下的汇编语言称为AT&T syntax。
- GNU的汇编器(即下文中的GAS)采用AT&T syntax,如 gcc -S filename.c 会生成AT&T syntax风格的汇编代码文件filename.s,如果想要生成Intel syntax风格的汇编代码,可以使用 gcc -S -masm=intel filename.c 命令。
- Intel syntax和AT&T syntax在编码上最大也是最应引起注意的区别是:两者指令的原操作数和目的操作数的位置正好是相反的。
GAS vs NASM
这是两种不同的汇编器,
- GAS是GNU Assembler的简写,基于AT&T syntax指令,生成.s文件。
- NASM是Netwide Assembler的简写,基于Intel syntax指令,生成.asm文件。
- 还有其它汇编器,如MASM (Microsoft Macro Assembler)、FASM (Flat Assembler)、TASM (Turbo Assembler)、YASM (Yet Another Assembler)等。常见汇编器的对比如下图所示
masm组织伪指令
- 段定义语句
为了与存储器的分段结构相对应,所以汇编指令也提供了对应的段的组织方式
段名 SEGMENT [定位类型] [组合类型] [‘类别’]
段名 ENDS
;数据段 |
段使用设定语句
ASSUME 段寄存器名: 段名 [, 段寄存器名: 段名, 段寄存器名: 段名 ..]
设定了段之后汇编程序需要知道各自段对应是用来干嘛的,并设置对应的段寄存器ASSUME CS: CSEG,DS:DSEG
ASSUME 是伪指令,所以汇编编译器其实是将其转换成了对应的汇编指令,所以ASSUME可以出现在代码段的任何位置。随时进行切换
DSGE1 SEGMENT |
汇编编译器在汇编的时候使用汇编地址计算器来计算每条指令的偏移地址,而ORG指令就是用于手动修改当前地址的
$表示当前指令的第一个字节的地址
org $+8
表示表示地址计算器从此处开始向后空8个字节出来
jmp $+ 6
转跳到本条指令之后6个字节处,注意计算地址是JMP指令的开始位置不是结束位置,所以这6个自己包含了JMP本身的长度
nasm伪指令
组织伪指令
SECTION是一种组织代码和存储的方式
- NASM支持标准的.data, .text和.bss,编译后的程序文件中的内存地址顺序是.text, .data,用户自定义section。
- NASM支持用户自定义section
- 同名的section,编译后会放在同一块连续的内存上
- 对用户自定义section,按照出现的先后顺序存储,同名的section存储在一起。
SECTION .data |
编译后,内存为0xB8040000 0102,其中0xB804是MOV AX,0x04的机器码,0x04是标号var1汇编后的偏移地址。因为汇编后,var1对应的存储区在.data段,被挪到了内存的尾部,因此偏移不是0x00,而变成了0x04。
每个SECTION默认都是按4字节对齐的:SECTION的对齐方式可以用ALIGN来调整
SECTION .s1 |
编译后产生的内存:0x01020000 0x03 可以看到SECTION .s1被扩展为4个字节,后面两个字节填0,然后是SECTION .s2
$$指向当前section相对于段基址的偏移地址,$指向当前行相对于段基址的偏移地址。
初始化数据:db 家族
| 数据类型 | 大小 | 伪指令 | 含义 |
|---|---|---|---|
| byte | 8 | 位 | db define byte |
| word | 16 | 位 | dw define word |
| dword | 32 | 位 | dd define doubleword |
| qword | 64 | 位 | dq define quadword |
| tword | 80 | 位 | dt define tword |
| oword | 128 | 位 | do define oword |
| yword | 256 | 位 | dy define yword |
db 0x55 ; just the byte 0x55 |
非初始化数据:resb 家族
resb 相当于 Microsoft MASM 语法中的 db ?
| 伪指令 | 含义 |
|---|---|
| resb | reserve byte |
| resw | reserve word |
| resd | reserve doubword |
| resq | reserve quadword |
| rest | reserve tword |
| reso | reserve oword |
| resy | reserve yword |
buffer: resb 64 ; reserve 64 bytes |
包含 binary 文件
asm 提供了一种包含 binary(二进制)文件的方法:使用 incbin 伪指令。incbin 伪指令包含的 binary 文件将直将写入输出文件中。此伪指令的作用是包含 graphics 以及 sound 这类数据文件。
incbin "file.dat" ; include the whole file |
$标号和times重复
$ 标号表示 nasm 编译后当前指令位置
$$ 标号表示当前 section 起始位置
times 510-($-$$) db 0 |
使用equ定义常量
equ 用来为标识符定义一个 整型 常量,它的作用类似 C 语言中的 #define
a equ 0 ; OK |
例子中: b 定义为常量 'abcd' 它将是字符串的 ASCII 码序列,‘abcdefghi' 常量将会被截断,整型常量最长为 quadword(8 bytes),而 d 企图被定义为一个 float 常量,这产生会错误。len 和 textlen 被定义为编译期确定的数值。
调试工具
DOS程序加载过程
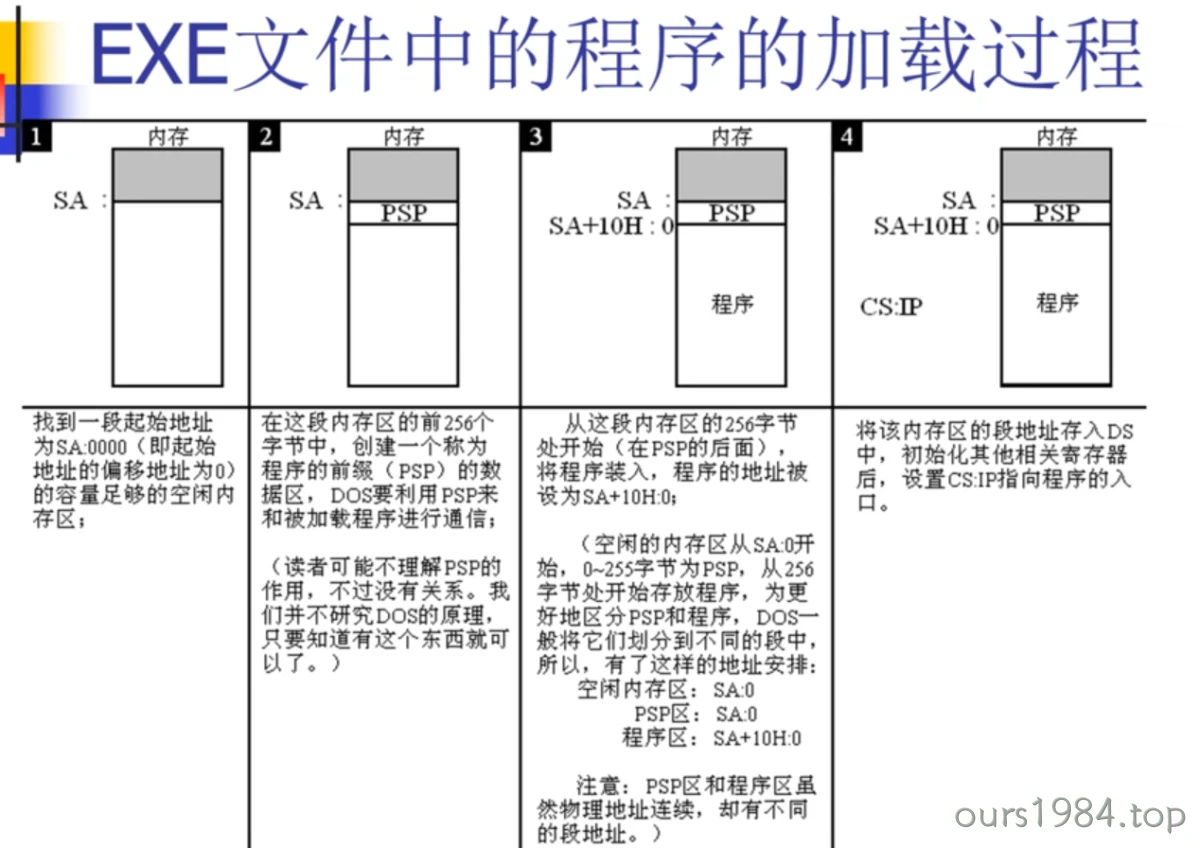
CX中存放了程序长度
windows调试
windows下使用dosbox学习调试
在vscode中直接安装MASM/TASM插件即可.右键就可以调试
DOSBox下debug命令
| 参数 | 含义 |
|---|---|
| -g | 执行到指定ip |
| -a | 编写汇编命令 |
| -t | 单步执行 |
| -p | 直接执行完不是单步执行 |
| -u | 反编译 |
| -r | 查看修改寄存器的值 |
| -d | 查看内存单元 |
| -e | 修改内存单元 |
| -? | 查看指令帮助 |
vscode安装以下插件进行调试
data segment ;数据段 |
linux调试
安装 |
| nasm参数 | 说明 |
|---|---|
| -f | elf是表示生产elf格式的目标文件,elf32,elf64 |
| -g | 是生产调试信息到目标文件 |
| -l | hello.lst对应的是指令和数据在段中偏移量,不要这个也可以 |
ld: warning: cannot find entry symbol _start; defaulting to 0000000000401000
原因:链接器在做程序链接的时候没有找到 _start 这个符号。(_start 是 arm 汇编程序的入口)
解决方法:在 _start 前面加上声明
. global _start。
section .data |
注意在源代码中加:global main main:,因为程序的入口函数是main,就像c中我们要写个main函数一样,gcc连接器在连接的时候就是找这个main标号,其实在目标代码中它就是一个符号名。
和调试c语言一样,直接用gdb hello命令进入调试。
具体调试指令可以参考gdb指令gdb汇编