LZ77压缩算法
LZ77算法是无损压缩算法,由以色列人Abraham Lempel发表于1977年。LZ77是典型的基于字典的压缩算法,现在很多压缩技术都是基于LZ77。
信息熵
数据为何是可以压缩的,因为数据都会表现出一定的特性,称为熵。绝大多数的数据所表现出来的容量往往大于其熵所建议的最佳容量。比如所有的数据都会有一定的冗余性,我们可以把冗余的数据采用更少的位对频繁出现的字符进行标记,也可以基于数据的一些特性基于字典编码,代替重复多余的短语。
LZ77原理
LZ77压缩算法采用字典的方式进行压缩,是一个简单但十分高效的数据压缩算法。其方式就是把数据中一些可以组织成短语(最长字符)的字符加入字典,然后再有相同字符出现采用标记来代替字典中的短语,如此通过标记代替多数重复出现的方式以进行压缩。
LZ77的主要算法逻辑就是,先通过前向缓冲区预读数据,然后再向滑动窗口移入(滑动窗口有一定的长度),不断的寻找能与字典中短语匹配的最长短语,然后通过标记符标记。
while input is not empty do |
压缩说明
- LZ77是基于字典的算法,和霍夫曼编码不同,其处理的符号不一定是文本字符,可以是任何大小的符号。
- LZ77使用前向缓冲区(待编码区的小段)和一个滑动窗口(搜索区)实现。
- 滑动窗口是个历史缓冲器,它被用来存放输入流的前n个字节的有关信息。
- 前向缓冲区是与动态窗口相对应的,它被用来存放输入流的前n个字节。
- 常用滑动窗口4KB,前向缓冲区32B
算法主要思想就是在前向缓冲区中不断寻找能够与字典中短语匹配的最长短语。
如果匹配的数据长度大于最小匹配长度,那么就输出一对〈长度,距离滑动窗中对应的位置〉数组。
长度(length)是匹配的数据长度,而距离(distance)说明了在输入流中向后多少字节这个匹配数据可以被找到。
LZ77算法中代价最高的是滑动窗口中扫描匹配短语。一个更高效的方法是用某种高效搜索性能的数据结构代替滑动窗口。
LZ77比霍夫曼编码有更好的压缩比,但是压缩过程中LZ77要消耗相当长的时间。
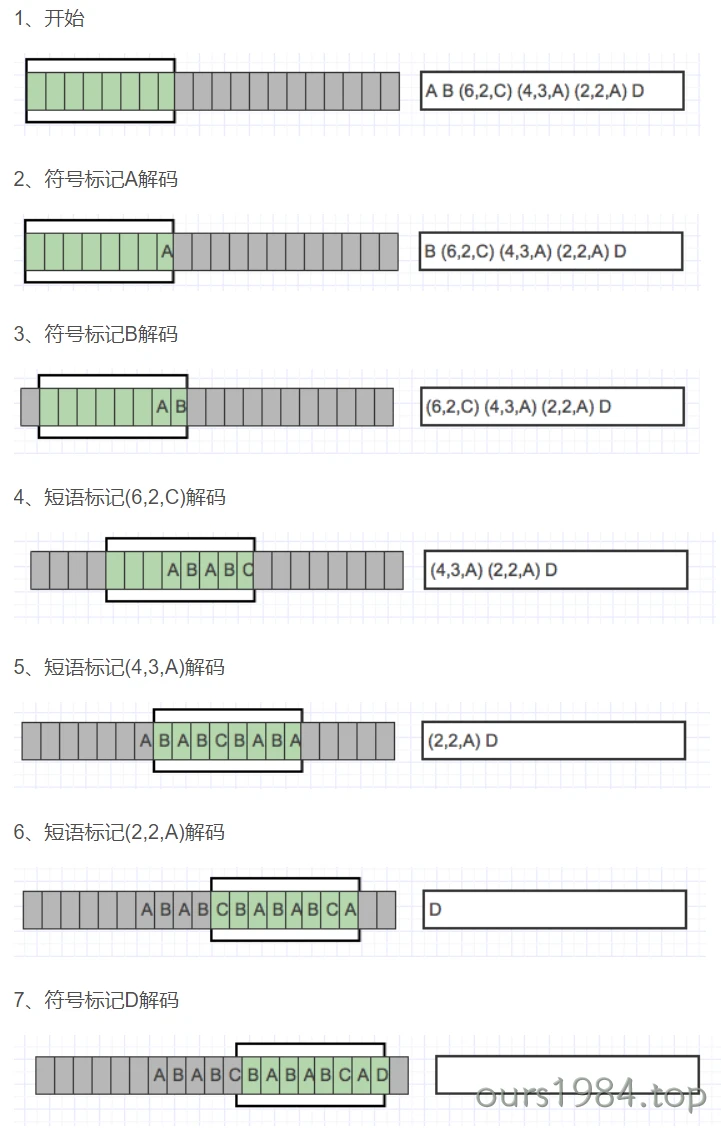
解压说明
解压类似于压缩的逆向过程,通过解码标记和保持滑动窗口中的符号来更新解压数据。
当解码字符标记:将标记编码成字符拷贝到滑动窗口中
解码短语标记:在滑动窗口中查找响应偏移量,同时找到指定长短的短语进行替换。
大多数情况下LZ77压缩算法的压缩比相当高,当然了也和选择滑动窗口大小,以及前向缓冲区大小,以及数据熵有关系。
其压缩过程是比较耗时的,因为要花费很多时间寻找滑动窗口中的短语匹配,不过解压过程会很快,因为每个标记都明确告知在哪个位置可以读取了。
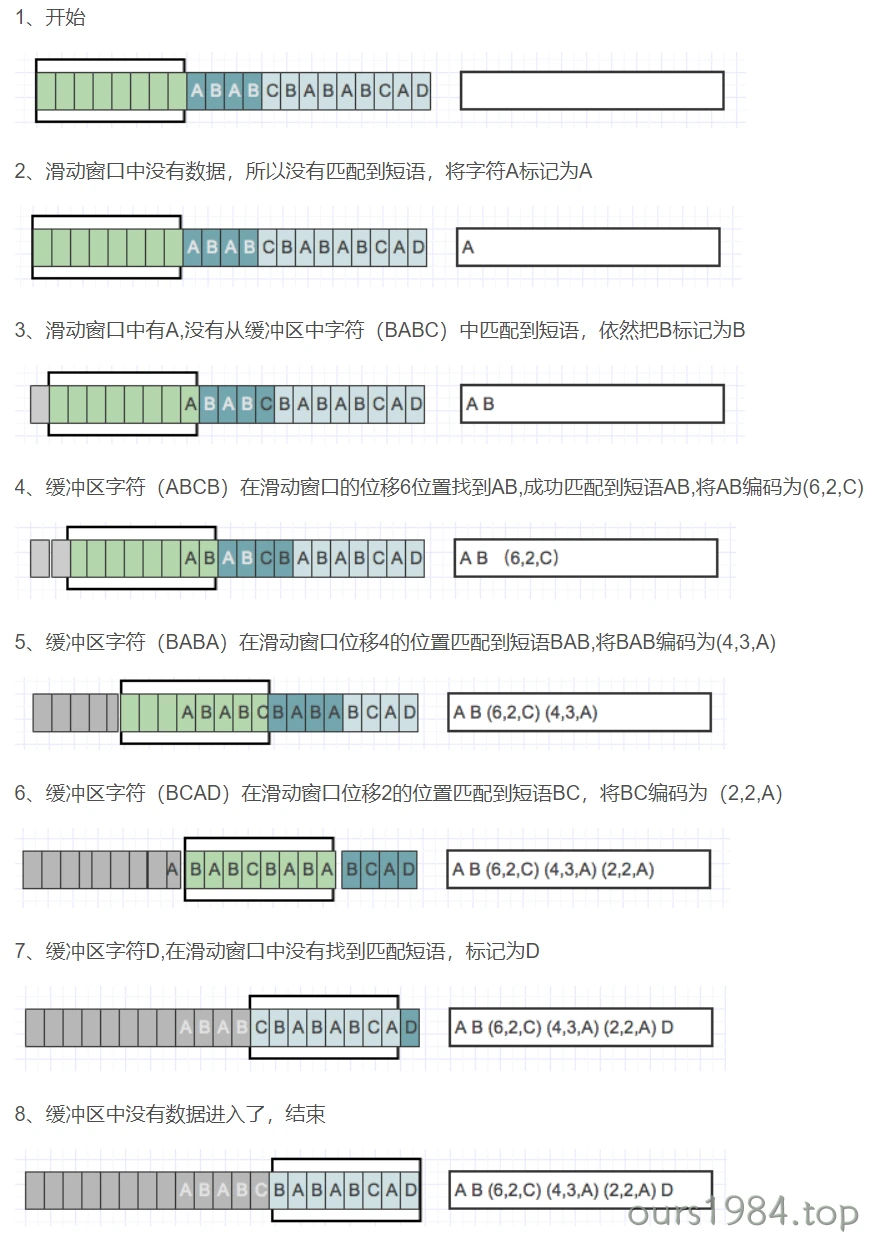
压缩示例
当压缩数据的时候,前向缓冲区与移动窗口之间在做短语匹配的是后会存在2种情况:
- 找不到匹配时:将未匹配的符号编码成符号标记(多数都是字符本身)
- 找到匹配时:将其最长的匹配编码成短语标记。
- 短语标记包含三部分信息:(滑动窗口中的偏移量(从匹配开始的地方计算)、匹配中的符号个数、匹配结束后的前向缓冲区中的第一个符号)。
一旦把n个符号编码并生成响应的标记,就将这n个符号从滑动窗口的一端移出,并用前向缓冲区中同样数量的符号来代替它们,如此,滑动窗口中始终有最新的短语。
解压示例