快速排序
- 学习分而治之。有时候,你可能会遇到使用任何已知的算法都无法解决的问题。优秀的算法学家遇到这种问题时,不会就此放弃,而是尝试使用掌握的各种问题解决方法来找出解决方案。
- 学习快速排序——一种常用的优雅的排序算法。快速排序使用分而治之的策略。
分而治之(divide and conquer,D&C)——一种著名的递归式问题解决方法。
只能解决一种问题的算法毕竟用处有限,而D&C提供了解决问题的思路,是另一个可供你使用的工具。
面对新问题时,你不再束手无策,而是自问:“使用分而治之能解决吗?”
分而治之
使用D&C解决问题的过程包括两个步骤。
- 找出基线条件,这种条件必须尽可能简单。
- 不断将问题分解(或者说缩小规模),直到符合基线条件。
假设你是农场主,有一小块土地。你要将这块地均匀地分成方块,且分出的方块要尽可能大。
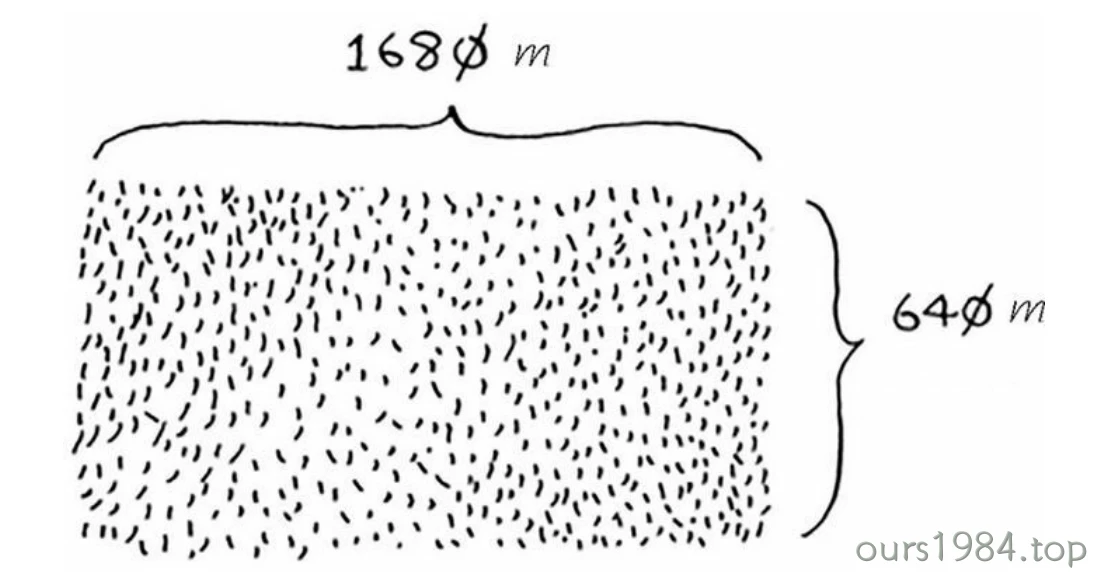
首先,找出基线条件。最容易处理的情况是,一条边的长度是另一条边的整数倍。
现在需要找出递归条件,这正是D&C的用武之地。根据D&C的定义,每次递归调用都必须缩小问题的规模。
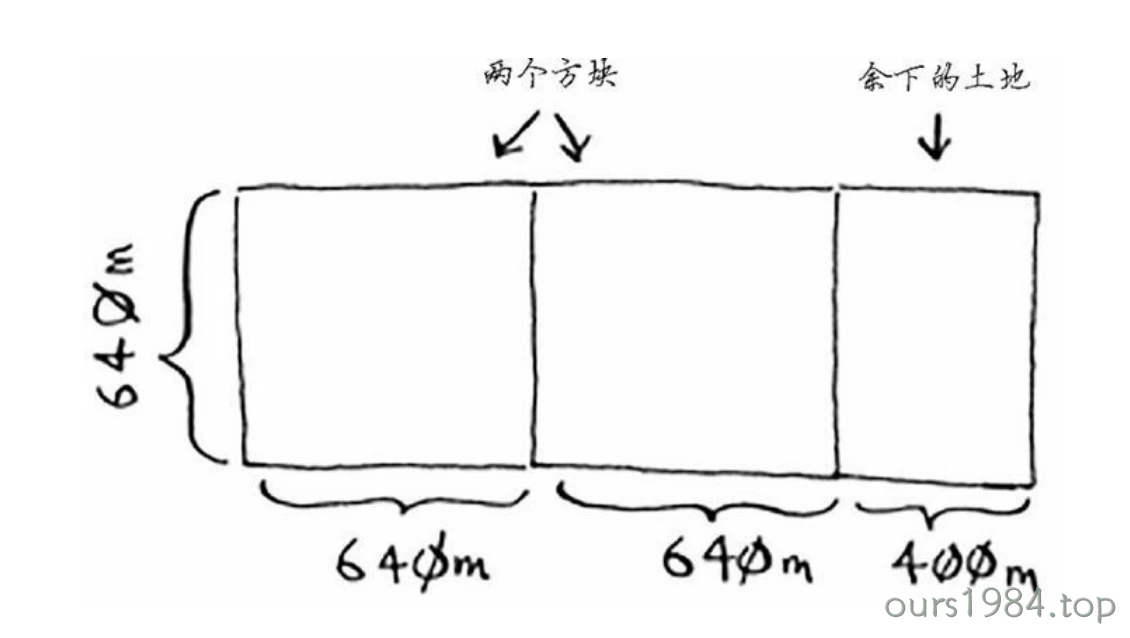
你可以从这块地中划出两个640 m×640 m的方块,同时余下一小块地。现在是顿悟时刻:何不对余下的那一小块地使用相同的算法呢?
“适用于这小块地的最大方块,也是适用于整块地的最大方块” 辗转相除法,了解一下
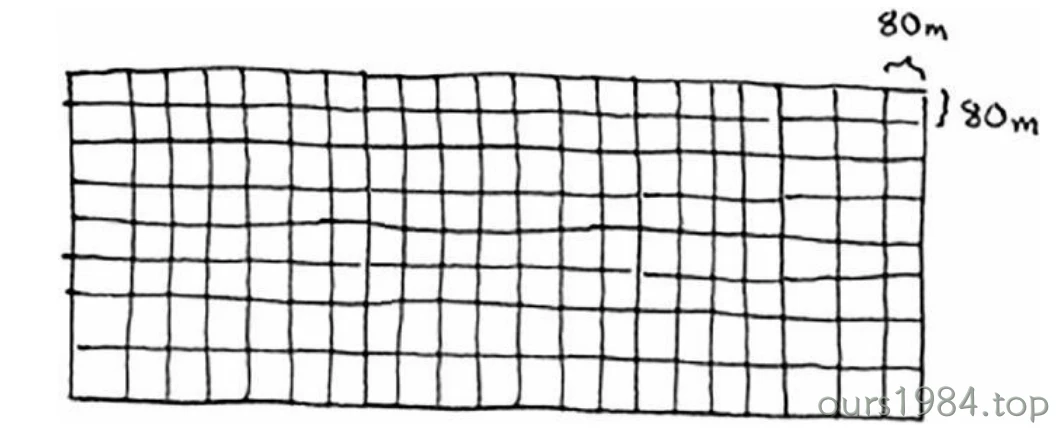
这里重申一下D&C的工作原理: (1) 找出简单的基线条件; (2) 确定如何缩小问题的规模,使其符合基线条件。 D&C并非可用于解决问题的算法,而是一种解决问题的思路。
快速排序
快速排序是一种常用的排序算法,比选择排序快得多。例如,C语言标准库中的函数qsort实现的就是快速排序。快速排序也使用了D&C。
基线条件为数组为空或只包含一个元素。在这种情况下,只需原样返回数组——根本就不用排序。
需要将数组分解,直到满足基线条件。使用分区(partitioning),将数组操作为以下状态
- 一个由所有小于基准值的数字组成的子数组;
- 基准值;
- 一个由所有大于基准值的数组组成的子数组。
只要对这两个子数组进行快速排序,再合并结果,就能得到一个有序数组
def quicksort(array): |
再谈大O表示法
快速排序在最糟情况下,其运行时间为O(n2)。与选择排序一样慢!但这是最糟情况。在平均情况下,快速排序的运行时间为O(n log n)。
常量的影响可能很大,对快速查找和合并查找来说就是如此。快速查找的常量比合并查找小,因此如果它们的运行时间都为O(nlog n),快速查找的速度将更快。实际上,快速查找的速度确实更快,因为相对于遇上最糟情况,它遇上平均情况的可能性要大得多。
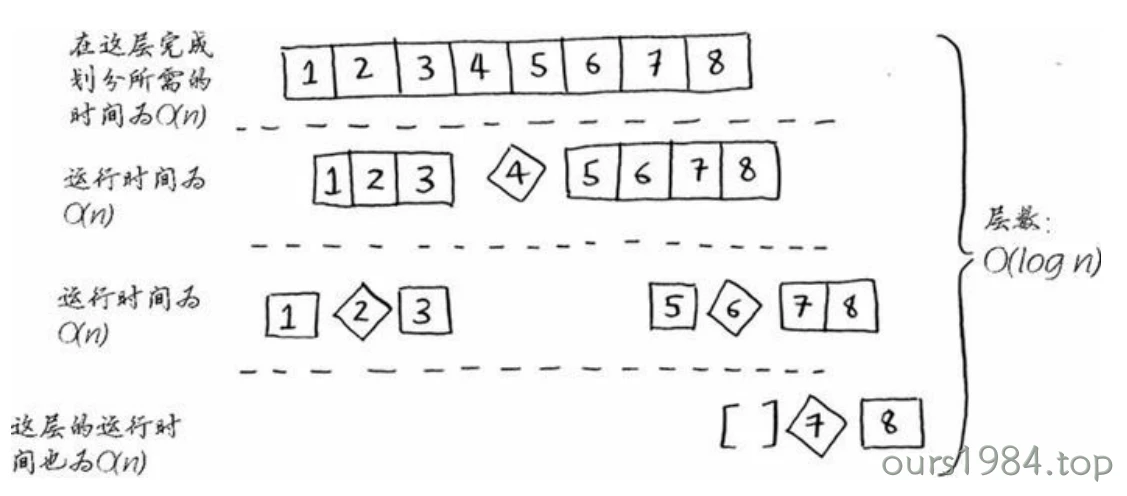
层数为\(O(log n)\)(用技术术语说,调用栈的高度为\(O(logn)\)),而每层需要的时间为\(O(n)\)。因此整个算法需要的时间为\(O(n) *O(log n) = O(n log n)\)。这就是最佳情况。
在最糟情况下,有\(O(n)\)层,因此该算法的运行时间为\(O(n) * O(n) =O(n^2)\)。
最佳情况也是平均情况。只要你每次都随机地选择一个数组元素作为基准值,快速排序的平均运行时间就将为O(n log n)。快速排序是最快的排序算法之一,也是D&C典范。
小结
- D&C将问题逐步分解。使用D&C处理列表时,基线条件很可能是空数组或只包含一个元素的数组。
- 实现快速排序时,请随机地选择用作基准值的元素。快速排序的平均运行时间为O(n log n)。
- 大O表示法中的常量有时候事关重大,这就是快速排序比合并排序快的原因所在。
- 比较简单查找和二分查找时,常量几乎无关紧要,因为列表很长时,O(log n)的速度比O(n)快得多。
如果你在哪儿卡住了,可以到这里查看源码。