机器学习入门知识

机器学习是人工智能的一个分支,主要关于构造和研究可以从数据中学习的系统
监督学习(Supervised)
训练数据包含标签y (标签在训练数据中是可见变量)
从标签的数据中学习到一个x → y的映射f,从而对新输入的x进行预测f(x)
监督任务类型
- 分类(Classification):输出y为离散值
- 回归(Regression):输出y为连续值
- 排序(Ranking)
监督工作流程
graph LR
A[TrainingData]--"estimator.fit(X_train,y_train)"-->B((Model))
C[TrainingLabels]-->B
B--"estimator.predict(X_test)"-->E
D[TestDtata]-->E((Prediction))
E-->G
F[TestLabels]--"estimator.score(X_test,y_train)"-->G((Evaluation))非监督学习(Unsupervised)
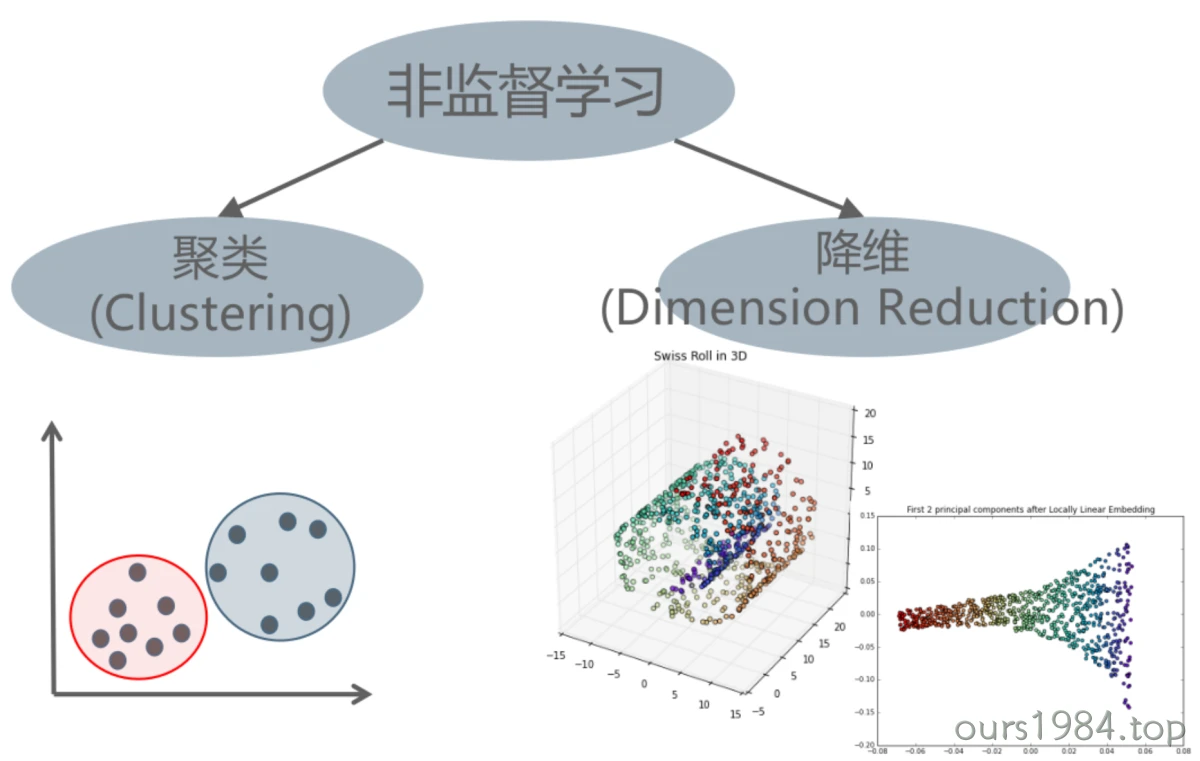
发现数据中的“有意义的模式”,亦被称为知识发现
训练数据不包含标签,标签在训练数据中为隐含变量
非监督任务类型
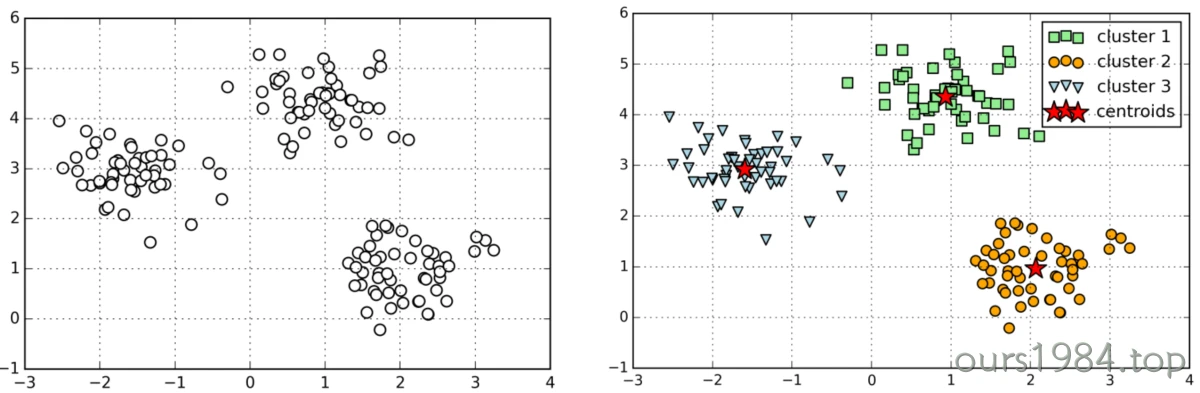
聚类(Clustering)
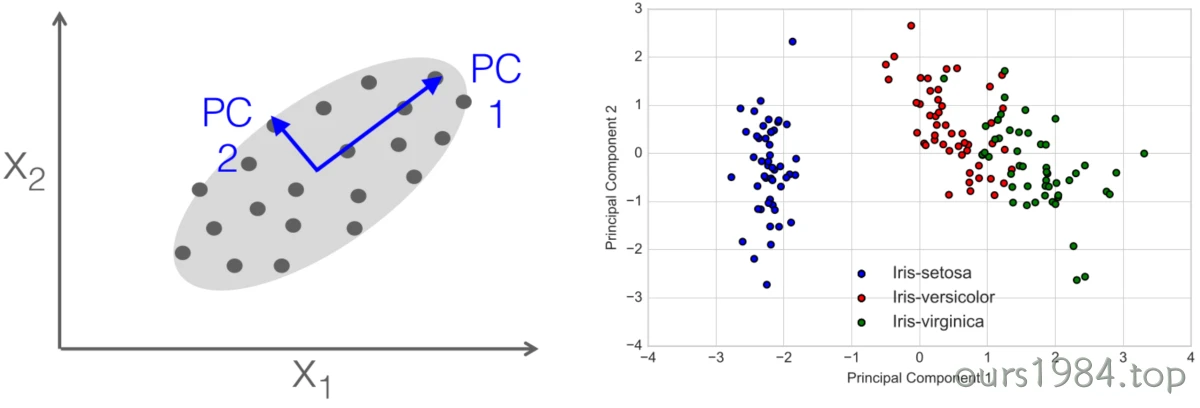
降维(Dimension Reduction)
概率密度估计(Density estimation)
非监督工作流程
graph LR
A[TrainingData]--"transformer.fit(X_train)"-->B((Model))
B--"transformer.transform(X_train)"-->E
D[TestDtata]--"transformer.transform(X_test)"-->E((New View))增强学习(Reinforcement)
根据延迟的奖励,通过“做”来学习
任务:找到一条回报值最大的路径
设计一个回报函数(reward function)
如果learning agent(如机器人、回棋AI程序)在执行一个动作后
获得了较好的结果,那么我们给agent一些回报(比如回报函数结果为正)
若得到较差的结果,则回报函数为负
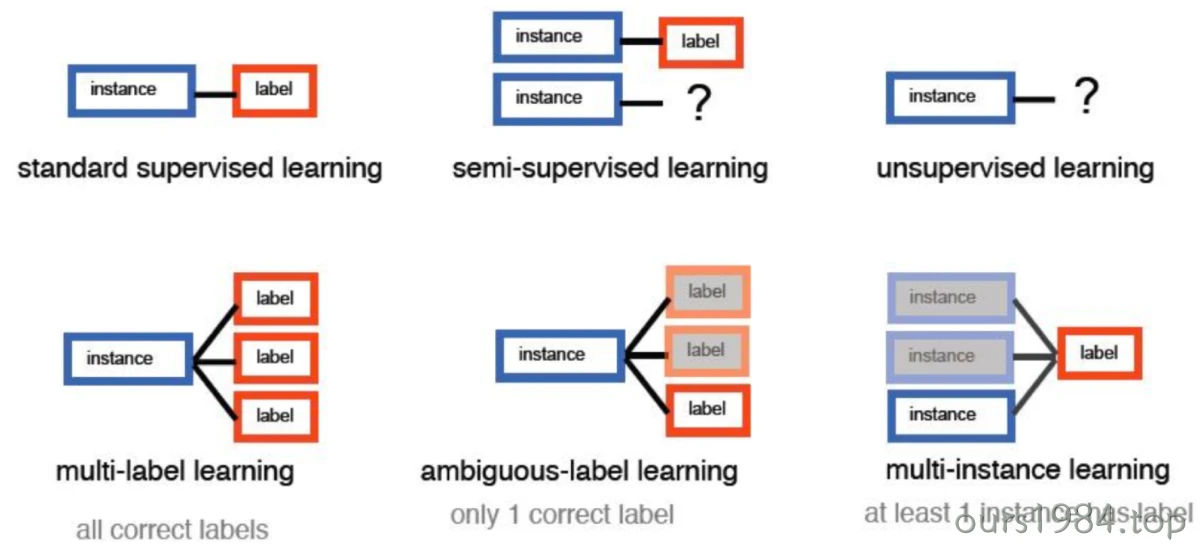
其他学习任务
工具软件
推荐直接安装Anaconda, 包括
- 很多有用的工具包(包括 Pandas 和Scikit-Learn)
- The Jupyter Notebook (IPython Notebook)
- conda package manager
- Spyder IDE

数据处理工具包
NumPy(Numeric Python)
Python的开源数值计算扩展,可用来存储和处理大型矩阵,具有以下特点
N维数组( ndarray )
实用的线性代数、傅里叶变换和随机数生成函数
NumPy和稀疏矩阵运算包SciPy配合使用更加方便
SciPy(Scientific Library for Python)
- SciPy 是建立在NumPy基础上、是科学和工程设计的 Python 工具包,提供统计、优化和数值微积分计算等功能
- 处理106 级别的数据通常没有大问题,但当数据量达到107级别时速度开始发慢, 内存受到限制 (具体情况取决于实际内存大小)
- 当处理超大模数据集,比如1010级别, 且数据中包含大量的 0时,可采用稀疏矩阵可显著的提高速度和效率
Pandas(Panel data structures)
- Python语言的“关系数据库”数据结构和数据分析工具,非常高效且易于使用
- 基于 NumPy补充了大量数据操作功能,能实现统计、分组、排序、透视表(SQL语句的大部分功能)
- 2 种重要数据类型:Series:一维序列,DataFrame:二维表(机器学习数据的常用数据结构)
数据可视化工具包
Matplotlib
Python语言的2D图形绘制工具
Seaborn
基于Matplotlib的Python可视化工具包,提供更高层次的用户接口,可以给出漂亮的数据统计图
机器学习工具包
Scikit-learn简介
对Python语言有所了解的科研人员可能都知道SciPy——一个开源的基于Python的科学计算工具包。基于SciPy,目前开发者们针对不同的应用领域已经发展出了为数众多的分支版本,它们被统一称为Scikits,即SciPy工具包的意思。而在这些分支版本中,最有名,也是专门面向机器学习的一个就是Scikit-learn。
Scikit-learn项目最早由数据科学家David Cournapeau 在2007 年发起,需要NumPy和SciPy等其他包的支持,是Python语言中专门针对机器学习应用而发展起来的一款开源框架。
它的维护也主要依靠开源社区。
Scikit-learn特点
作为专门面向机器学习的Python开源框架,Scikit-learn可以在一定范围内为开发者提供非常好的帮助。它内部实现了各种各样成熟的算法,容易安装和使用,样例丰富,而且教程和文档也非常详细。
另一方面,Scikit-learn也有缺点。例如它不支持深度学习和强化学习,这在今天已经是应用非常广泛的技术。此外,它也不支持图模型和序列预测,不支持Python之外的语言,不支持PyPy,也不支持GPU加速。
看到这里可能会有人担心Scikit-learn的性能表现,这里需要指出的是:如果不考虑多层神经网络的相关应用,Scikit-learn的性能表现是非常不错的。究其原因,一方面是因为其内部算法的实现十分高效,另一方面或许可以归功于Cython编译器;通过Cython在Scikit-learn框架内部生成C语言代码的运行方式,Scikit-learn消除了大部分的性能瓶颈。
Scikit-learn主要类
Scikit-learn的基本功能主要被分为六大部分:分类,回归,聚类,数据降维,模型选择和数据预处理。
- Preprocessing 预处理 · 应用:转换输入数据,规范化、编码化 · 模块:preprocessing,feature_extraction,transformer(转换器)
- Dimensionality reduction 降维 · 应用:Visualization(可视化),Increased efficiency(提高效率) · 算法:主成分分析(PCA)、非负矩阵分解(NMF),feature_selection(特征选择)等
- Classification 分类 · 应用:二元分类问题、多分类问题、Image recognition 图像识别等 · 算法:逻辑回归、SVM,最近邻,随机森林,Naïve Bayes,神经网络等
- Regression 回归 · 应用:Drug response 药物反应,Stock prices 股票价格 · 算法:线性回归、SVR,ridge regression,Lasso,最小角回归(LARS)等
- Clustering 聚类 · 应用:客户细分,分组实验结果 · 算法:k-Means,spectral clustering(谱聚类),mean-shift(均值漂移)
- Model selection 模型选择 · 目标:通过参数调整提高精度 · 模块:pipeline(流水线),grid_search(网格搜索),cross_validation( 交叉验证),metrics(度量),learning_curve(学习曲线)